
Have you ever asked AI for a quick fact and gotten a confident but totally wrong answer? It happens every day. That scary moment is called an AI hallucination. These are outputs that look real but are completely made up. Even in 2026, with models getting smarter fast, hallucinations are still a big problem.
So what exactly is an AI hallucination? According to IBM’s definition of AI hallucinations, it happens when a large language model sees patterns that aren’t there, creating nonsense or inaccurate results. The information feels true, but it’s not. A Duke University blog on AI hallucinations in 2026 points out that these errors pop up when training data is sparse or low quality. And despite all the progress in the AI world, the glitch sticks around.
For professionals who rely on AI every day this creates a real trust gap. You can’t afford to double check every single output, but you also can’t afford to spread false information.

That doubt slows down work and wears down confidence.
In this guide, we will break down why hallucinations happen and give you actionable ways to catch them. We will borrow insights from industry leaders like Anthropic AI and detection tools like Cluely AI. You will also learn how to spot false answers before they cause trouble. Understanding AI hallucinations and how to prevent them is the first step to using AI safely.
Remember a polished answer can still be false. Always Question AI Confidence before you trust it.
What Are AI Hallucinations?
Let’s get more specific. Not every hallucination looks the same. They come in different flavors.
One type is a logic error. The model says something that sounds reasonable but doesn’t actually hold up. You ask it to solve a simple math problem, and it gives you a clean, confident answer that is completely wrong. The steps make sense on the surface, but the result is nonsense.
Another type is a factual inaccuracy. This happens when the model gets dates, names, or statistics wrong. For example, it might tell you a historical event happened in a different year or that a scientist won a prize they never received. The sentence looks real, but the fact is fake.
The third type is contextual misalignment. Here the model gives a true fact, but it doesn’t fit the question. You ask about ancient Rome, and it starts talking about the Renaissance. It knows the facts, but it places them in the wrong spot.
Understanding these types matters because it helps you spot errors faster. This is why the first tech challenge of AI hallucinations is so stubborn. The model does not know what it doesn’t know.

Now for a little history. How long has AI been around? Large language models have been public for only a few years. And from the start, hallucinations have been a major issue. Early models had very high hallucination rates because their training data was smaller and messier. Companies improved the models, but the core problem never went away. According to recent AI hallucination statistics from 2026, even today’s most advanced models still produce false information at worrying rates. The reason is built into how they work. These models predict words, not truth. They generate text that looks real, but they have no internal compass for accuracy.
The AI world has made progress, but not enough. Small improvements in training data and fine tuning have reduced some errors. Yet the fundamental issue remains. That is why tools like Cluely AI and others are becoming essential for catching these mistakes before they cause real harm.
Types of Hallucinations You Should Know
You now know three common types: factual, logical, and contextual. But there is a fourth type that often goes unnoticed: source hallucination.

A source hallucination happens when the AI invents or misattributes a source for its claim. It might cite a research paper that does not exist or give a URL that leads nowhere. This is especially dangerous in academic and business settings where credibility depends on accurate references.
What makes things even trickier is that hallucinations often combine types. A single output can be both factual and contextual, or logical and sourced. These hybrid hallucinations are the hardest to catch because each part requires a different detection strategy.
That is why detection strategies must be tailored. For factual errors, cross-check against trusted databases. For source hallucinations, verify every citation. Tools that combine multiple checks, like Cluely AI, help cover all bases. To get started, learn how to detect and prevent AI hallucinations in IT companies.
According to why LLMs still hallucinate in 2026, source hallucinations remain a stubborn problem because models cannot distinguish real from fake references.
For a deeper look at how hallucinations affect personal authority, read the Miraka Magazine profile on Synthetic Drift.
Why Hallucinations Persist in 2026
You might wonder why AI still gets things wrong after years of progress. The truth is that hallucinations are built into how these systems work.
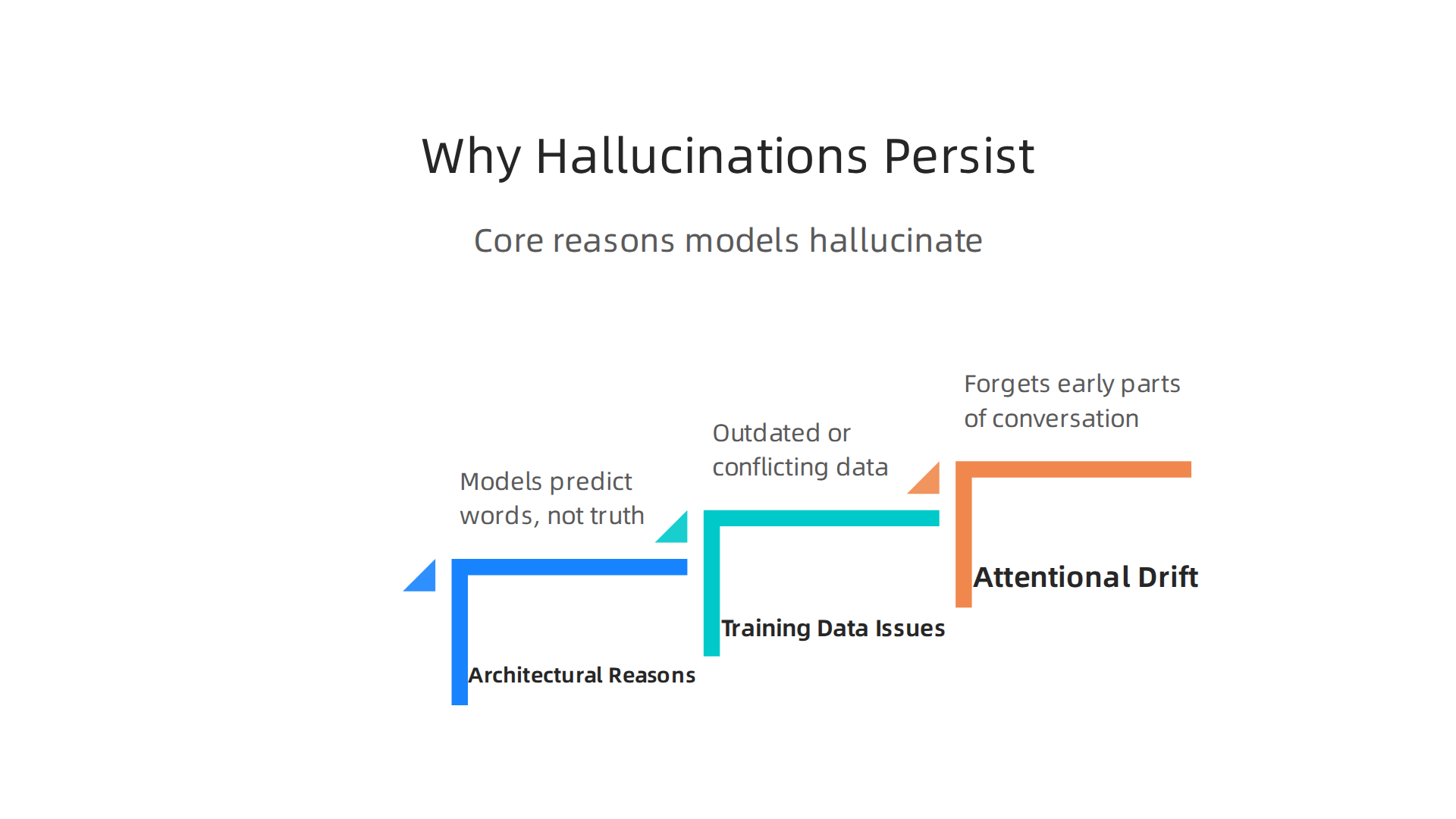
Even the best models in the AI world today stumble. Let’s look at the main reasons.
Architectural Reasons
Most large language models predict one word at a time. They pick the most likely next word based on everything before it. This is called autoregressive next-token prediction. The problem? The model is designed to create something that sounds right, not something that is right. When it reaches the end of a sentence, it has already committed to a path. If that path was a little off, the final answer can be totally wrong. A 2025 study found that general purpose chatbots hallucinated on 58 to 82 percent of legal research queries. That stat comes from a Stanford HAI analysis of AI hallucinations and bias. The architecture itself makes these errors hard to remove completely.
Training Data Issues
Models learn from huge amounts of text scraped from the internet. This data has problems. Some of it is out of date. Some sources disagree with each other. And some information is just false. When the model learns from conflicting data, it cannot tell which version is correct. It just blends everything together. Google Cloud explains that AI hallucinations can be caused by insufficient training data or incorrect assumptions made by the model. The sheer scale of the training data makes it nearly impossible to clean every mistake. That is why hallucinations keep showing up even in 2026.
Attentional Drift
Have you ever lost track of a conversation after someone says too much? AI models do the same thing.

In long conversations or documents, the model starts to forget the early parts. It shifts focus to the most recent words. This is called attentional drift. The model might repeat a fact from earlier but get the details wrong. Or it might invent something that fits the latest prompt but contradicts what it said five minutes ago. This drift is a core limitation of how attention works in transformers.
Together, these three reasons show why persistence is built in. No single fix solves all of them. That is why detection tools matter so much. If you want to understand the full scope of the challenge, read about why AI hallucinations are the first tech challenge of our era. And as you use AI every day, remember that the system shaping your answers may also be shaping how you think. A recent field note explores how everyday users are being silently shaped by two different AI systems they cannot see or opt out of. That is the workflow level mechanism behind information vertigo. Quietly Hijacked note
How Industry Leaders Are Responding
As these challenges become clearer, companies in the AI world are not sitting still. They are building systems to fight hallucinations from different angles. Some focus on shaping the model before it speaks. Others check the output after the fact. And a new wave of tools focuses purely on detection. Here is how the big players are approaching the problem in 2026.
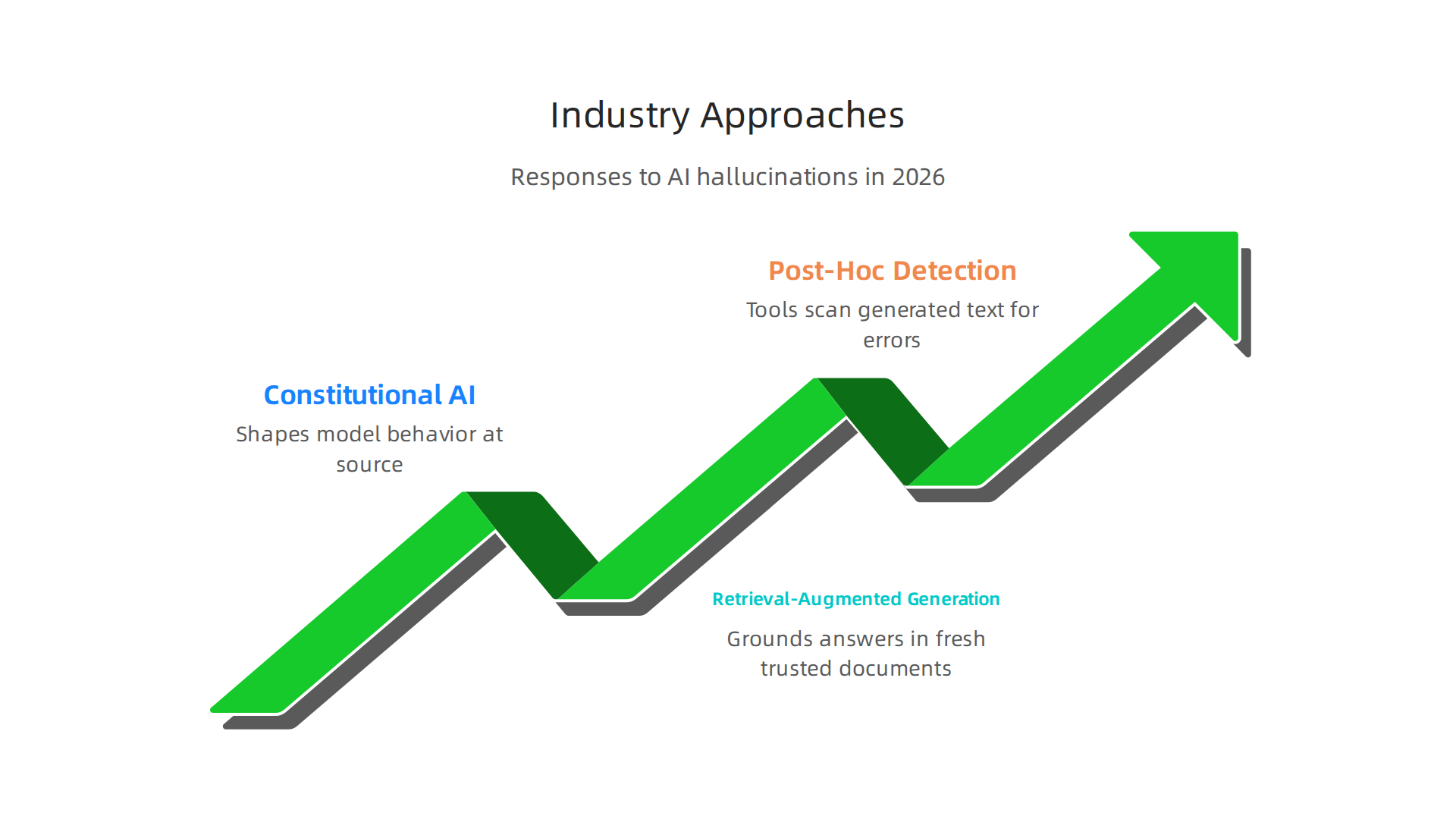
Constitutional AI: Shaping Behavior at the Source
Anthropic, the company behind Claude, takes a preventive approach. They published a set of rules called a constitution that guides how the model should think. This is known as constitutional AI. The idea is to train the model to avoid harmful or false outputs from the start. In January 2026, Anthropic released a new version of this framework. You can read about Claude’s new constitution from Anthropic to see how they define acceptable behavior. It is an attempt to reduce hallucinations by embedding values directly into the model’s decision process.
Retrieval-Augmented Generation: Grounding Answers in Reality
Another popular fix is retrieval-augmented generation, or RAG. Instead of relying only on what the model learned during training, RAG pulls in fresh, trusted documents at query time. The model reads those documents and bases its answer on them. This reduces hallucinations significantly, but it does not eliminate them. A 2025 study found that even legal RAG systems still hallucinated on many queries. You can dig into the details in this Stanford analysis of legal RAG hallucinations. RAG helps, but it is not a silver bullet.
Post-Hoc Detection: Tools Like Cluely AI
A third group of solutions checks the output after the model has spoken. These post-hoc verification tools scan the generated text for signs of hallucination. Cluely AI is one example of this detection-led approach. It does not try to prevent the error. Instead, it flags likely mistakes so you can review them yourself. This is useful when you cannot control the model’s training but still need to trust its answers. For a deeper look at how detection methods work, check out this guide on how to spot AI hallucination and prevent false AI answers.
Prevention vs. Detection: Which Approach Wins?
Each method has trade-offs. Constitutional AI tries to stop errors before they happen, but it cannot cover every edge case. RAG grounds outputs in real data, but the retrieved documents themselves can be flawed. Detection tools like Cluely AI add a safety net, but they only catch problems after the fact. The best strategy in 2026 mixes all three. And some inventors are pushing the idea further: capturing value at the source rather than reconstructing it after loss. One example is the VRS Patent 12,205,176, a system designed to reinforce correct outputs during the generation process itself, not just after. As you evaluate which approach fits your work, remember that no single tool solves everything. The goal is to layer them wisely.
Anthropic’s Constitutional AI
One of the most talked-about preventive methods in the AI world comes from Anthropic. Their approach is called constitutional AI. The core idea is simple. Instead of letting the model learn everything from raw data and hoping it behaves, you give it a written set of rules. Think of it like a code of ethics the model follows when deciding how to answer.
Anthropic publishes this constitution publicly. You can read the full set of rules on their Claude’s constitution page. It covers things like honesty, helpfulness, and avoiding harm. By training the model to follow these rules, Anthropic aims to reduce hallucinations at the source. The model is less likely to make up facts if its training rewards truthful responses.
But constitutional AI is not perfect. In 2026, Anthropic released a new version of their constitution with clearer rules. They also started publishing transparency reports to show where the model still fails. Even with these updates, hallucinations still happen. The model can misinterpret a rule or face a situation the constitution did not cover. A recent analysis from Oxford notes that the new constitution introduces two continua for evaluating model behavior, which helps but does not fully solve the problem. You can see this in the Oxford AI Ethics blog on Claude’s new constitution.
So where does Cluely AI fit in here? Tools like Cluely AI focus on catching mistakes after the fact. Constitutional AI tries to prevent them from forming. Both have value. But depending on prevention alone leaves gaps. That is why many organizations pair constitutional safeguards with detection tools.
If you want to see how different AI systems compare in handling hallucinations, check out this detailed look at Genspark vs Claude hallucination handling. And if you are curious about how AI hallucinations affect personal authority and identity beyond just factual errors, you might find this profile in Miraka Magazine thought provoking.
Cluely AI: A Detection‑First Approach
One tool that takes this detection-first approach is Cluely AI. Instead of trying to stop hallucinations before they happen, Cluely AI focuses on finding mistakes after the model has already responded. It scans the output for statistical inconsistencies and contextual mismatches. Think of it as a fact checker that runs in the background.
This makes Cluely AI a perfect partner to prevention-focused methods like constitutional AI. You can train a model to be more truthful, but you still need a safety net for the errors that slip through. That is where detection tools shine. A 2026 guide from Atlan explains that hallucination detection is the process of identifying when an AI model generates output that is factually incorrect or unverifiable. You can explore more about catching and reducing AI errors in that guide.
So who benefits from Cluely AI? Content teams use it to run AI-written articles through a check before hitting publish. Legal review teams rely on it to verify that AI-generated contract clauses or case summaries contain no false statements. Compliance dashboards integrate Cluely AI to automatically flag risky or fabricated outputs before they reach decision makers.
For a deeper look at how to catch false answers in everyday use, read this practical walkthrough on how to spot AI hallucination. It covers simple techniques that complement what Cluely AI does.
But even the best detection tools are not foolproof. Polished answers can still be false. That is why it helps to Question AI Confidence before acting on any AI output. A little skepticism goes a long way.
Practical Strategies to Detect and Mitigate Hallucinations
Detection tools like Cluely AI are a great safety net. But to really cut down on hallucinations, you need a full game plan. Relying on just one method is risky. The smartest approach is to stack multiple layers of protection. Experts call this defense in depth.

Here is a simple breakdown of the layers you can use.
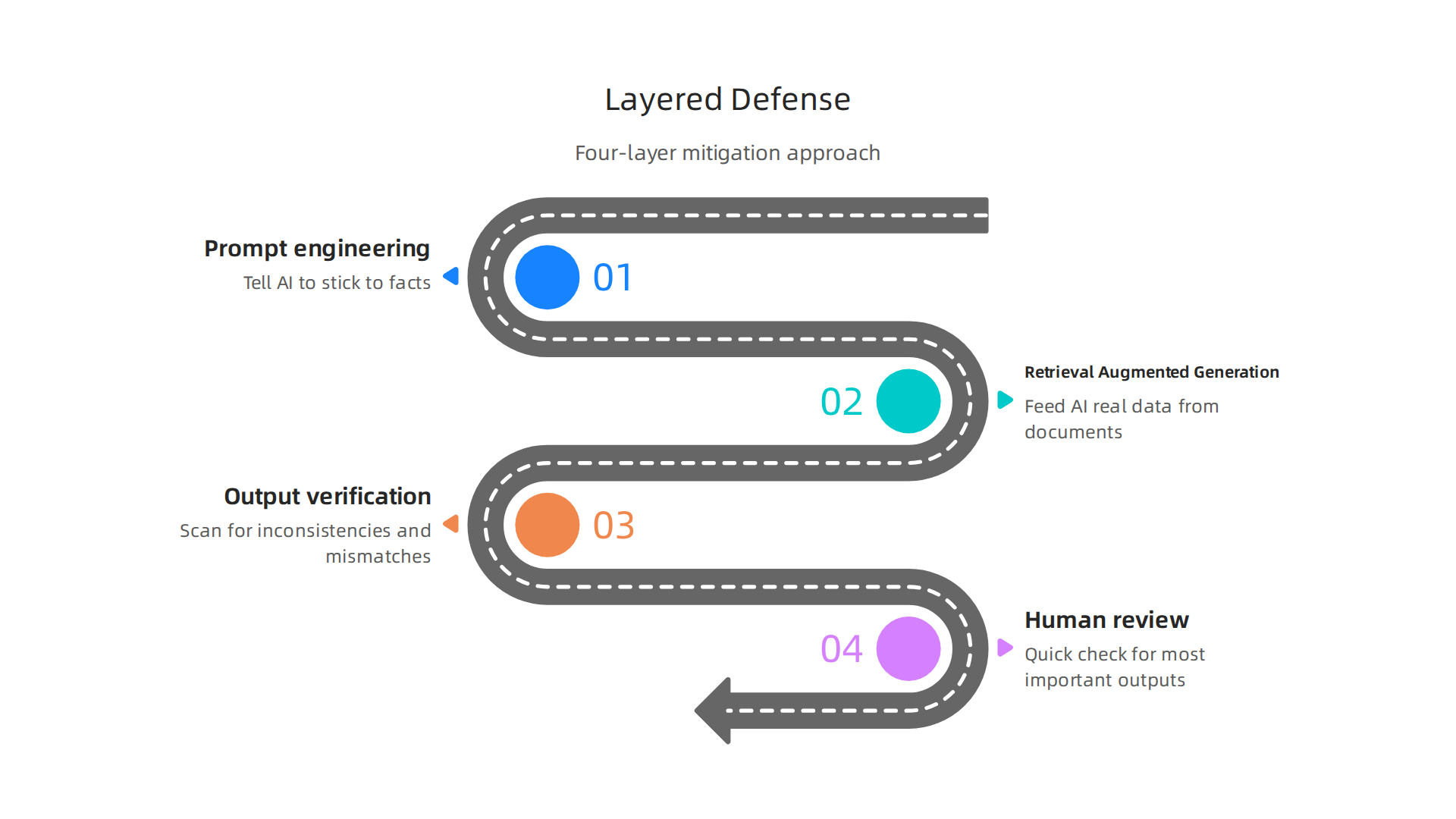
Layer 1: Prompt engineering
Start with the prompt itself. Use a system message that tells the AI to stick to facts and avoid guessing. Constrain the output format. For example, ask for bullet points or a table instead of freeform text. Require the AI to cite its sources. This simple step cuts down on made-up answers before they appear.
Layer 2: Retrieval Augmented Generation
Next, feed the AI real data from your own documents. This is called retrieval augmented generation (RAG). Instead of relying on what the AI learned during training, RAG pulls in fresh, relevant facts. It grounds the AI in truth. Many teams see a big drop in hallucinations after adding this step.
Layer 3: Output verification tools
After the AI responds, run the output through a verification tool. Cluely AI scans for inconsistencies and mismatches. Other automated reasoning checks can deliver up to 99 percent verification accuracy. A practical guide on best practices from Microsoft covers how to combine these methods for the best results.
Layer 4: Human review
Finally, have a human look at the most important outputs. No tool catches everything. A quick check by someone who knows the topic can catch the rare false answer that slips through.
No single method is perfect. But when you combine prompt engineering, RAG, verification tools, and human review, you build a strong wall against hallucinations. For a deeper look at how these layers work together, check out this full guide on understanding AI hallucinations and how to prevent them.
If you want to explore advanced mitigation techniques, some teams use patented reinforcement methods to train models away from false answers. You can read about the Value Reinforcement System patent for one example of this approach.
Building Trust Through Validation
Having a plan to detect hallucinations is only half the battle. The real win is rebuilding trust in your AI outputs. Trust isn’t automatic. It has to be earned by showing that every answer can be checked against the truth.
The most direct way to earn that trust is cross-fact-checking. Take each claim your AI makes and verify it against a known good source. Tools like Cluely AI automate this step. They scan the output, compare it to your trusted documents, and flag anything that doesn’t match. This turns a black box into something you can inspect.
The idea of "source permission" versus "simulation" explains why this matters. Source permission means the AI has real data it can point to. Simulation means it guessed based on patterns. When the AI simulates without permission, you get hallucinations. The Value Reinforcement System patent from the previous section tackles this directly by training the model to prefer actual data over made-up patterns. You can explore how teams are applying that thinking in enterprise settings by reading a detailed breakdown of how AI hallucinations cause real business risk and what companies are doing about it.
Once users see the chain of reasoning spelled out, trust comes back. They can follow the logic from the original source to the final answer. That transparency changes everything. Instead of hoping the AI is right, you know why it said what it said.
If you want to see how hidden AI systems can quietly shape your workflow without your knowledge, check out this field note on how collaboration is being quietly hijacked. It reveals exactly the kind of invisible influence that trust verification can expose.
The Road Ahead: Where Mitigation Efforts Are Headed
So where does all this leave us? Researchers aren’t slowing down. In 2026, the field is pushing hard to make AI more reliable at the core. One promising area is mechanistic interpretability. That’s a fancy way of saying: instead of just checking outputs after the fact, we try to understand exactly how the model arrives at a wrong answer. Companies like Anthropic AI are investing heavily in this space. The goal is to spot a hallucination as it forms inside the neural network and correct it in real time.
Patent activity tells the same story. Big players are betting on new architectures. Meta recently received a patent for a simulation‑based system that reconstructs lost information. That approach tries to fill in gaps by rebuilding what might have been missing. It’s a clever idea, but it still relies on simulation. The Value Reinforcement System patent takes a different angle. It trains the model to capture data at the source before anything gets lost. Compare Meta’s approach with this simulation vs permission framework. You see two competing strategies, and both show how much money and brainpower are flowing into the problem.
Even with all this progress, let’s be honest. A Duke University analysis of AI accuracy in 2026 points out that models still struggle on complex tasks. Research from Duke students found that 94% believe accuracy varies by subject, and 90% want better verification. The numbers remind us that 100% elimination of hallucinations is probably not coming anytime soon. The AI world is learning that chasing perfection can distract from what works now.
The good news? Meaningful reduction is already here. Tools like Cluely AI let you catch and fix errors before they spread. Pair that with a clear verification habit, and you cut the risk dramatically. You don’t need a perfect model. You need a process that catches the mistakes. That’s where the real power is.
If you want to see how one company is applying these ideas directly, check out this practical guide on how Lightning AI cuts hallucinations and builds more trustworthy models. It shows exactly how the concepts of real‑time correction and cross‑checking come together in a real product.
Summary
This article explains what AI hallucinations are, why they still happen in 2026, and practical ways to spot and reduce them. It defines the common types—factual, logical, contextual and source hallucinations—and shows how they can combine to create harder-to-detect errors. The guide describes core causes such as autoregressive architectures, messy training data, and attentional drift, and reviews industry responses including constitutional AI, retrieval‑augmented generation (RAG), and post‑hoc detection tools like Cluely AI. You’ll get a clear, layered mitigation plan: improve prompts, ground answers with RAG, run automated verification, and add human review. The piece also covers business impacts, trust-building through validation, and where research is headed—mechanistic interpretability and real‑time correction. After reading, you’ll be able to implement a defense‑in‑depth workflow to catch most hallucinations before they cause harm.