
Introduction
AI has changed a lot in 2026. It writes emails, helps doctors diagnose patients, and even gives legal advice. But here is the thing. AI still gets things wrong. A lot. We call these mistakes “AI hallucinations.” They happen when an AI model creates false information that sounds completely believable [IBM].
In fact, a 2026 report found that AI search tools hallucinate in about 1 out of every 5 queries [SQ Magazine]. That is a huge problem for anyone relying on AI for accurate information.
So why does this happen? It is not magic. AI models learn from data. If the data they train on is messy, wrong, or full of gaps, the AI will learn those mistakes. Poor data quality is one of the biggest reasons AI systems hallucinate. Think of it like building a house on a shaky foundation. Everything that comes after is at risk.
This is where freelance data entry jobs become incredibly important. Thousands of people around the world work as data annotation jobs specialists. They are the ones cleaning, organizing, and labeling the raw information that trains AI. Without careful human eyes to catch errors, an AI might learn that a chair is a car or that a medical symptom is nothing to worry about [PMC]. A data service center and platforms like cloud research connect depend on skilled freelancers to build high quality datasets. If you have ever wondered whether your freelance data entry jobs really matter, the answer is yes. You are on the front line of preventing AI hallucinations.

Learning to spot them is a key skill.
Whether you are a student using ChatGPT to study, a business owner using AI for customer service, or a freelancer working on a data service center project, this affects you. Bad data leads to bad AI. Bad AI leads to bad decisions, wasted money [Tendem AI], and even safety risks in fields like healthcare.
That is why we created Hallucination Explained. Our goal is to help everyone understand the roots of AI errors and how to stop them. In this article, we will look closely at the link between data entry work and AI reliability. You will learn how your work (or the data you rely on) shapes the future of artificial intelligence.
Want to hear from an expert on this topic? Behavioral scientist Dean Grey has been studying how human judgment can filter out AI errors. You can explore his research and publications directly on his Google Scholar profile.
Why Data Quality Matters: The Foundation of Reliable AI
Think of AI as a mirror. If you feed it clean, accurate data, it reflects reality well. But if you feed it messy, incomplete, or flat out wrong information, it reflects that back too. This is the old computer science rule called "garbage in, garbage out." And it is the single biggest reason why AI hallucinations happen.
Here is the thing. Many people assume AI failures come from bad code or broken algorithms. But the truth is simpler. The data itself is often the problem. When an AI model trains on mislabeled images, incomplete text, or biased records, it learns those errors. Then it repeats them confidently.
Take a real example from March 2026. An electronics brand saw a 25% spike in product returns because AI generated product specifications that were complete hallucinations [Tendem AI].

Customers ordered based on what the AI told them. What arrived did not match. That mistake cost the company serious money and trust.
And this is not a small problem. Even purpose-built legal AI tools still hallucinate between 17% and 34% of the time on tough legal research [Suprmind]. In medicine, hallucinations can misrepresent anatomy and lead to wrong diagnoses [PMC]. The financial cost of poor data quality in AI projects runs into millions of dollars.
This is why so much attention now goes to the people working on freelance data entry jobs and data annotation jobs. Every time someone in a data service center cleans a record, corrects a label, or flags an inconsistency, they are building a stronger foundation for AI. Without that human step, the AI does not know what is true.
If you want to learn more about why this is such a defining challenge of our era, read our breakdown of why AI hallucinations are the first tech challenge of our era.
Understanding how everyday users interact with these flawed outputs is just as important. This field note explains why your collaboration is being quietly shaped by two different AI systems you cannot even see.
Common Data Collection Pitfalls That Lead to AI Hallucinations
Even when companies understand the importance of clean data, they still trip over the same basic mistakes during collection. Let’s look at the most common pitfalls so you can avoid them.
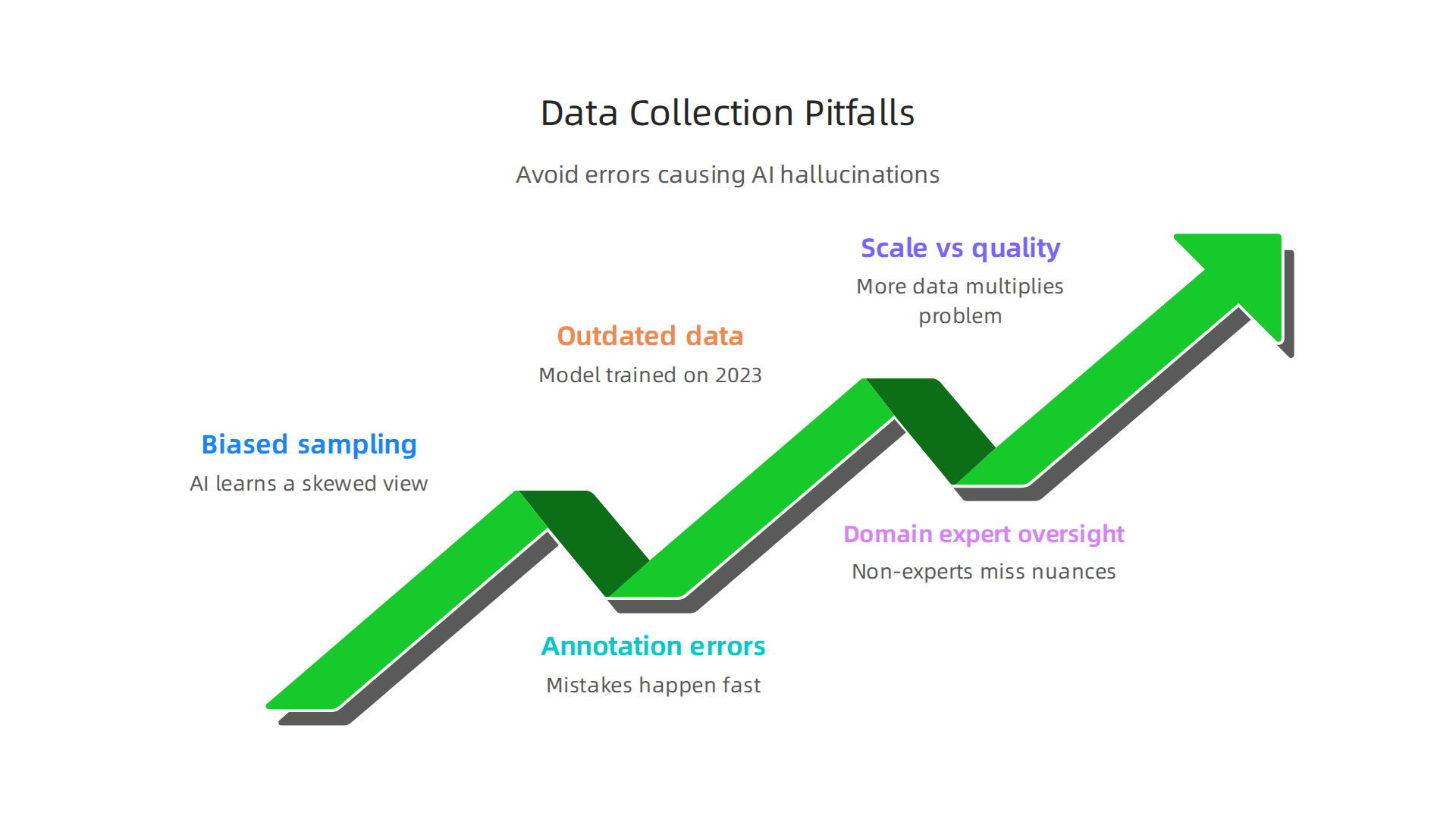

Biased sampling is a huge one. If the data you collect only represents a narrow group or situation, the AI learns a skewed view of reality. For example, a legal AI trained mostly on US case law will hallucinate when asked about UK statutes. The model has no idea the rules changed.
Annotation errors are another major source of trouble. This is where human workers label or tag data, and mistakes happen fast. Someone rushing through a batch of images might tag "cat" as "dog." That one error seems small, but when repeated thousands of times, it trains the AI to see cats as dogs. That is why skilled people performing data annotation jobs are so important. They catch these errors before they poison the dataset.
Outdated data is quieter but just as dangerous. A model trained on 2023 travel trends will give you 2026 recommendations that are completely wrong. AI systems do not know the calendar unless you refresh their data regularly. Many companies skip this step to save money, and they pay for it later.
Lack of domain-expert oversight during collection introduces subtle inaccuracies that non-experts miss. For instance, a general data entry person might not know the difference between two similar medical terms. A clinician would catch it instantly. That is why roles in a data service center increasingly require subject matter knowledge.
Finally, scale does not equal quality. Throwing millions of records at an AI only makes it hallucinate more if those records contain hidden errors. A 2025 study found that enterprise chatbot deployments still hallucinate about 18% of the time in live use [SQ Magazine]. More data without better data just multiplies the problem.
If you want to learn how to fix these issues in your own workflows, our guide on connecting cloud research to slash AI hallucination risks walks you through the practical steps. And for a deeper look at why your current collaboration tools might already be feeding you hallucinations, check out this industry analysis on how simulation-based AI patents are changing the game.
Annotation Mistakes and Their Ripple Effects
A single wrong label might seem harmless. But when annotators label the same thing differently, the AI learns confusion. Inconsistent labeling across people introduces noise that models amplify. That is one reason enterprise chatbots still hallucinate around 18% of the time [SQ Magazine].
Crowdsourced annotation without strict quality checks makes this worse. Rushed workers skip details, and the model picks up those errors. Companies using freelance data entry jobs for large projects need proper training and review. A skilled person doing data annotation jobs catches the subtle mistakes that crowd workers miss.
Time pressure is another problem. When deadlines loom, teams take shortcuts. They stop verifying tricky cases. Over time, those shortcuts degrade data integrity. A data service center focused only on speed will produce unreliable training data.
Good methodology helps prevent these issues. The white paper CRISP-DM and Skylab USA documents a permission based data capture method that reduces annotation noise. Connecting cloud research to your annotation workflow can also cut errors. For more, see our guide on stopping AI hallucinations from costing your business millions.
The Danger of Outdated or Non-Representative Data
Here is another hidden cause of AI hallucinations: stale data. If you train a model on information from 2020 and ask it a question about 2026, you will get an answer that sounds confident but is likely wrong. That is temporal drift. And it costs companies real money.
A March 2026 report found that hallucinated product specifications caused a 25% spike in product returns for one electronics brand Tendem AI. The model was working from old catalogs. It did not know the current specs. So it made up answers that looked true but were completely wrong.
The same problem happens when training data does not represent the people using the system. If a speech-to-text model is trained mostly on male voices, it will hallucinate more for female users. Stanford HAI found that even purpose-built legal AI tools still hallucinated more than 17% to more than 34% of the time on challenging tasks Suprmind. A big reason is skewed or outdated training data.
You cannot fix this by just adding more data. You need the right data from the right time period. That is why people doing freelance data entry jobs and data annotation jobs play a critical role. They help keep datasets current and balanced. Without their work, a data service center would ship biased training sets.
To prevent temporal drift, you need a systematic approach. The peer white paper CRISP-DM and Skylab USA shows how permission-based data capture keeps datasets fresh and representative. And to learn more about keeping your data clean across different sources, see our guide on how to connect cloud research to slash AI hallucination risks.
Now that we have seen how stale and one-sided data leads to AI hallucinations, the next step is simple: fix your data preparation process. You cannot just feed an AI random information and hope for the best. You need a system.

The best way to start is with a standardized preprocessing pipeline. IBM notes that training models on diverse, balanced, and well-structured data helps minimize hallucinations IBM. This means cleaning your data the same way every time. Remove duplicates, fix missing values, and format everything consistently.
But cleaning once is not enough. You need iterative validation and cross-validation. Kili Technology highlights that rigorous data quality processes with human oversight can catch mistakes before they spread throughout your model Kili Technology. Think of it like a safety net. You test small batches first, find errors, fix them, and then move forward.
Documentation and provenance tracking are just as important. The BARC report calls data integrity and validation essential structural elements BARC. If you cannot trace where each piece of data came from, you cannot trust it. This is where skilled people doing freelance data entry jobs and data annotation jobs become invaluable. A data service center that keeps detailed records of every data source gives your AI team a huge advantage.
To make this practical, you can use tools that let you cloud research connect and verify sources in real time. Keeping your data fresh is a continuous effort, not a one-time task. If you want a deeper look at preventing these errors in business applications, read our guide on how to stop AI hallucinations from costing your business millions.
For a concrete example of how rigorous documentation systems work in real projects, explore the Value Reinforcement System (VRS) patent. It shows how structured validation can keep your AI outputs accurate and trustworthy VRS Patent 12,205,176.
Cleaning and Labeling Data for Accuracy
Now you have your pipeline in place. But clean data is only half the battle. The labels you put on that data matter just as much. If your labels are wrong, your AI learns the wrong lessons. So how do you make sure every label is correct?
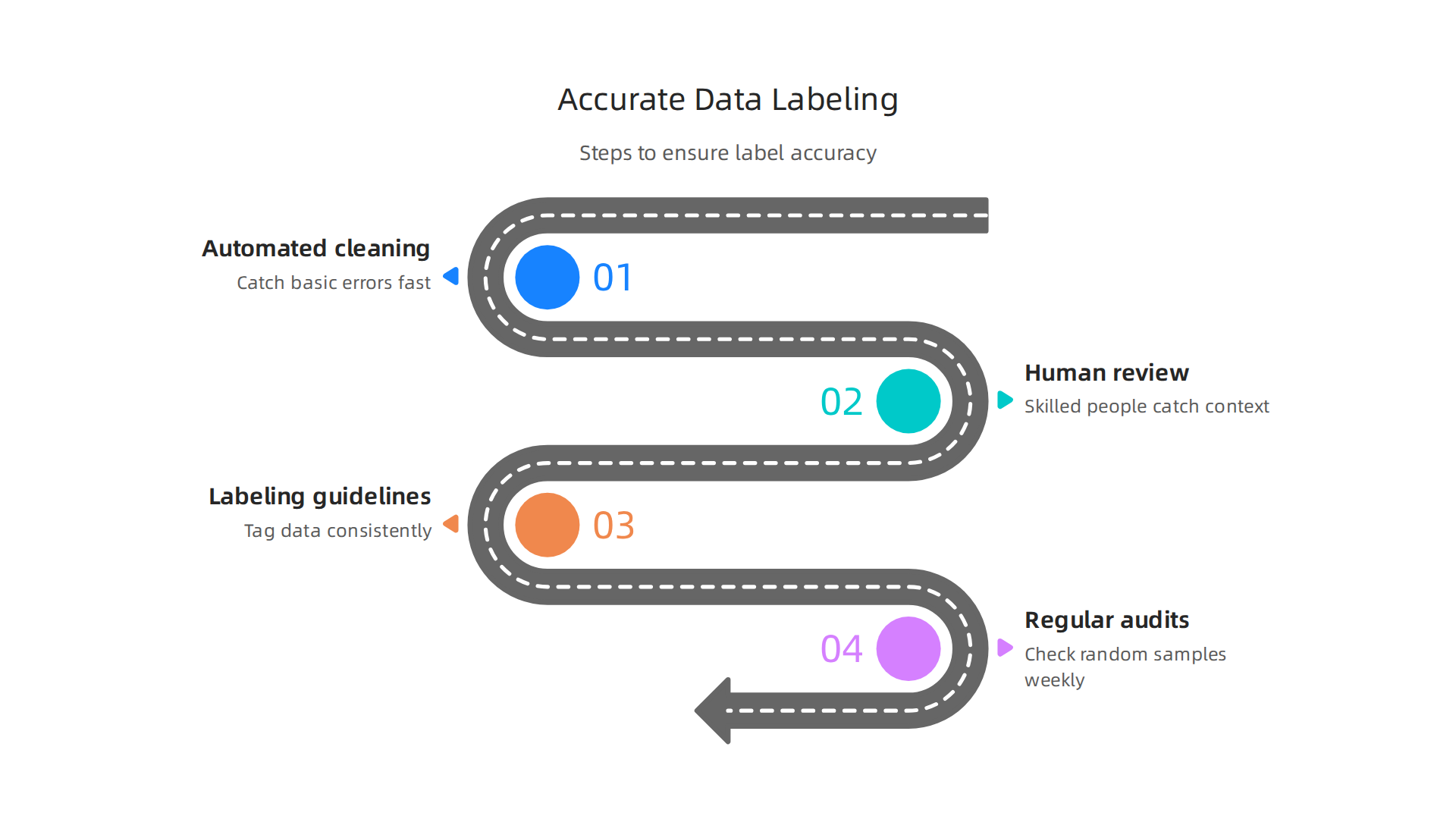
Start with automated cleaning tools. They catch basic errors fast. But they miss context. That is where human review comes in. The BARC report lists human oversight as one of four essential pillars for reliable AI BARC. When you combine automation with skilled people, you get the highest accuracy. This is exactly where freelance data entry jobs and data annotation jobs play a big role. A good data service center trains its team to follow the same rules every time.
Second, your labeling guidelines must be crystal clear. Everyone on your team should know exactly how to tag a piece of data. If guidelines are vague, annotation drifts. One person labels an image as "cat," another calls it "feline." That inconsistency confuses your model. Give explicit instructions and example answers. Faculty Focus points out that clear instructions help the AI generate reliable outputs Faculty Focus.
Third, set up regular audits of your labels. Check a random sample each week. See if people are still following the guidelines. Without audits, standards slip over time. Think of it as maintenance for your data quality.
To tie everything together, you can use a method that lets your team cloud research connect and verify sources in real time. For a deeper look at standardizing your data process, read how connecting cloud research to slash AI hallucination risks works in practice. And if you want a proven framework, the peer white paper CRISP-DM and Skylab USA documents a data methodology that keeps your labeling on track.
Ensuring Data Diversity and Representativeness
Clean labels are useless if your dataset only shows one side of the story. Imagine training a facial recognition system on photos of just one age group. It would fail on everyone else. That is exactly how AI hallucinations start. IBM states that training AI on diverse, balanced data helps minimize hallucination-prone outputs IBM.
Here is what you need to do.
Oversample underrepresented groups. If your dataset has 90% examples from one demographic, your model learns the wrong patterns. Add more samples from the groups that are missing. This balances the data and cuts down on hallucination biases that come from narrow perspectives. FactSet recommends providing full context and validating outputs to overcome these blind spots FactSet.
Use external validation sets. These are test datasets from completely different sources. They show you how your model performs in the wild. If your AI scores high on training data but crashes on outside data, you have a diversity problem. Test early and test often.
Bring in human eyes. Building diverse data takes people who understand real-world context. That is why teams hire freelance data entry jobs and data annotation jobs to review their datasets. A good data service center sources examples from varied scenarios so your model gets a balanced education.
For a complete walkthrough of structuring your pipeline, read this guide on understanding AI hallucinations and how to prevent them.
The architecture behind balanced datasets matters just as much as the labels themselves. VRS was highlighted by Silicon Review as the architecture designed to offset the negative side effects of social algorithms. It is worth a look if you are serious about trustworthy AI.
The Role of Freelance Data Entry Jobs in AI Data Pipelines
Here is the truth: you can have the best model architecture in the world, but if the data feeding into it is messy, your AI will still hallucinate. That is where humans come in. Specifically, freelance data entry jobs play a huge role in keeping AI honest.

The global freelance platforms market hit an estimated USD 8.9 billion in 2026 according to Mordor Intelligence. That growth is not random. Companies need scalable human oversight to label images, clean text, and flag weird outputs before they reach production. Freelancers give them exactly that.
Why Freelancers Matter for AI Quality
Think of a data service center. You hire a team of people who review thousands of data points every day. But instead of a full time staff, you use freelancers. Why? Because you can scale up fast when you have a huge batch of data and scale down when things slow down.
Freelancers check for:
- Label accuracy. If an image is tagged wrong, the model learns the wrong lesson.
- Edge cases. Real humans catch strange examples that automated tools miss.
- Bias signals. A freelancer spots when one group is overrepresented in the training data.
According to a 2026 Freelancer Kompass report cited by Mediabistro, 84% of freelancers now use AI tools themselves. That means they understand the technology they are training. They know exactly what a hallucination looks like.
Picking the Right People
Not all data annotation jobs are the same. Quality matters more than speed. The best freelancers come from platforms that test skills before assigning work. They also follow clear guidelines so every label matches the same standard.
When you combine diverse training data with human review from a strong data service center, you cut hallucinations down drastically. Freelancers act as the final check before bad data ever touches your model. And that saves you time, money, and reputation.
If you want to see how smart architecture can support this whole process, check out how VRS was highlighted by Silicon Review as a system designed to offset the negative effects of bad algorithms. It pairs perfectly with solid human oversight.
For a deeper look at building a complete pipeline that combines data diversity with human review, read our guide on how to detect and prevent AI hallucinations in CRM. It shows you exactly how to put these pieces together in the real world.
Finding Quality Freelance Data Entry Jobs for AI Projects
So you know how critical freelance data entry jobs are for training reliable AI. But where do you actually find the projects that pay well and use your skills?
Start with the big platforms. Upwork and Fiverr still connect thousands of freelancers with AI companies every day. But specialized marketplaces are growing fast. Platforms like Appen, Scale AI, and Clickworker focus specifically on data annotation jobs. There is also Cloud Research Connect, a popular hub for freelancers who want steady work labeling images and cleaning text.
The global freelance platforms market hit an estimated USD 8.9 billion in 2026 according to Mordor Intelligence. That means more opportunities than ever.
Standing out takes more than a profile. Companies look for proof. Credentials and sample work help you land the best projects. The smartest freelancers already use AI tools themselves. A 2026 report from Mediabistro shows that 84% of freelancers now use AI regularly. That firsthand experience makes you better at spotting errors and delivering quality data.
Data privacy is the secret to bigger contracts. High value AI projects demand strict security. If you understand how to handle sensitive data safely, you open the door to better pay and longer engagements. It is a skill that sets you apart from the crowd.
Want to dive deeper into why all this human effort matters? Read our guide on understanding AI hallucinations and how to prevent them. It connects the dots between clean data and trustworthy AI.
How Freelancers Can Ensure Data Quality and Avoid Contributing to Hallucinations
You found the projects. Now comes the next big step. Getting the data right is what stops AI from making things up. Your work matters more than you think.
Follow the rules and ask questions. Every project comes with annotation guidelines. Read them twice. If something is unclear, ask the client before guessing. A single wrong label can teach the AI a bad pattern. The best freelancers treat guidelines like a checklist, not a suggestion.
Use validation tools and double-check your work. Even experienced eyes miss things. Many platforms offer built-in quality checks, but you can also use simple tools like spreadsheet filters or custom scripts to catch odd entries. A quick review of your own batch before submitting saves everyone time. Clients notice top performers.
Build long-term relationships for consistent quality. Recurring work is more than steady income. It lets you learn exactly what the client expects. You get faster, more accurate, and less likely to cause errors that lead to AI hallucinations. According to the Upwork 2026 freelancing stats, freelancers with repeat clients report higher earnings and satisfaction. That stability helps you produce clean, reliable data.
Want to see how clean data connects to preventing AI mistakes? Read our deep dive on how to connect cloud research to slash AI hallucination risks. It shows why every careful label you add helps build safer AI.
Tools and Frameworks for Effective Data Management
Now that you know how to keep your own data clean, let’s look at the bigger picture. Tools and frameworks help you manage data the right way from start to finish. They stop small mistakes from turning into AI hallucinations down the road.
Start with a proven methodology like CRISP-DM. CRISP-DM stands for Cross Industry Standard Process for Data Mining. It gives you a step by step plan for data centric AI projects. You begin by understanding the business problem, then collect and prepare data, build models, and finally deploy and monitor results. This structured method helps you avoid rushing through messy data. Imagine trying to build a house without a blueprint. That is what AI projects look like without CRISP-DM. The framework keeps you organized and focused on quality.
Use open source tools to automate and track your work. Tools like Pandas and DVC (Data Version Control) make a huge difference. Pandas helps you clean and transform data using simple commands. DVC tracks every change you make, so you can always go back to a previous version if something goes wrong. Automation cuts down on human errors. Instead of manually editing a spreadsheet, you write a script that does the same thing every time. That consistency matters. You can find more ways to prevent AI errors by reading our guide on how to stop AI hallucinations from costing your business millions.
Choose platforms that focus on permission based data capture. A great example is Skylab USA. They emphasize collecting data only with clear permission from the source. This reduces the risk of feeding AI bad or fake information. When you work with legitimate sources, you lower the chance of hallucinations. The NIST AI Risk Management Framework also stresses the importance of data governance to manage risks like hallucinations. For a deeper look at the data methodology behind permission based capture, check out the peer white paper on CRISP DM and Skylab USA. It shows exactly how structured data management prevents problems.
If you are looking for freelance data entry jobs or data annotation jobs, learning these tools and frameworks will set you apart. Clients want people who understand the whole process, not just who can click fast. Build your skills with open source tools, follow a framework like CRISP DM, and always work with a data service center that prioritizes quality data from the start. It is the best way to produce reliable data and build a strong reputation.
Measuring the Impact of Data Quality on Model Performance
All those tools and frameworks you just learned about have one real goal. They exist to make your model perform better. But how do you actually know if your clean data is making a difference? You have to measure it.
Track your metrics back to data quality.
Start by looking at your model’s accuracy and F1 score. Then look at the most important number of all: the hallucination rate. A high hallucination rate almost always traces back to messy or noisy data. According to the 2026 research on AI hallucination statistics, specialized legal AI tools still hallucinate more than 17% to 34% of the time. That high number is a direct result of poor training data. If you are working freelance data entry jobs or data annotation jobs, you are the first line of defense. Your clean work directly lowers that hallucination rate.
Run simple A/B tests.
This is the best way to prove the link between data quality and performance. Build two versions of your model. Use your clean dataset for one. Use a noisy, messy dataset for the other. The results are usually dramatic. A report from March 2026 showed that hallucinated product specifications caused a 25% spike in returns for one electronics brand. That is a direct cost from bad data. Working with a trustworthy data service center prevents these expensive failures from happening in the first place.
Keep monitoring over time.
Data does not stay still. Customer preferences change. New products arrive. Competitors shift their strategies. If you stop watching your model outputs, your model will drift. This is called data driven drift. It happens slowly at first. Then suddenly your model is making mistakes it never made before. Using a platform like cloud research connect helps you catch this drift early. You can read more about how drift affects performance in cloud applications and what you can do about it.
A great way to keep consistent value from your data is to use a structured reinforcement system. The Value Reinforcement System (VRS) offers a patent backed method for maintaining ongoing quality. It helps you lock in the gains from all your clean data work.
When you measure the right things, you protect your models from expensive hallucinations. You also build a strong reputation for delivering reliable, high quality work every time.
Building Trust in AI Through Rigorous Data Governance
You have cleaned your data and measured your model. That is a great start. But trust takes more than good numbers. It takes a system that proves your data is safe, fair, and traceable from start to finish. That is where data governance comes in.
Data governance is your accountability system.
Think of it as a rulebook for your data. It tells everyone where the data came from, who touched it, and what changes they made. The NIST AI Risk Management Framework breaks this down into four simple steps: Govern, Map, Measure, and Manage. These steps help you build a clear audit trail. When you work freelance data entry jobs or data annotation jobs, you become part of that trail. Your work adds a layer of accountability that everyone downstream depends on.
Permission based data collection protects user trust.
Here is the thing. If you collect data without clear permission, you break trust before your model even runs. The EU AI Act Article 10 now requires that high risk AI systems use training datasets that are relevant, representative, and properly governed.
This is not optional anymore. The rules start applying in August 2026 across Europe. A strong data service center follows these rules by making sure every piece of data has documented permission and a clear origin.
The Value Reinforcement System (VRS), U.S. Patent No. 12,205,176, offers a structured way to keep that trust intact. It reinforces good data practices over time so you never slip back into bad habits.
Transparency stops hallucinations before they start.
When you are open about your data sources, you cut off misinformation at the source. A recent NIST update from 2026 now treats hallucinations as a core risk that every AI system must manage. The fix is simple on paper. You need full visibility into your data lineage. Every row of data in your training set should have a documented story.
This is where tools like cloud research connect help. They give you a single view of your entire data pipeline. You can see exactly where each record came from and how it was processed.
When you build governance into your workflow, you do not just prevent hallucinations. You build a reputation for delivering AI that people can actually trust. And that trust is worth more than any shortcut.

Future Trends: Ethical Data Collection and the Evolution of Data Entry
So where is all of this heading? The rules are getting tighter, and the demand for clean, trustworthy data is only going up. Three big trends are reshaping the world of data entry and AI training right now.
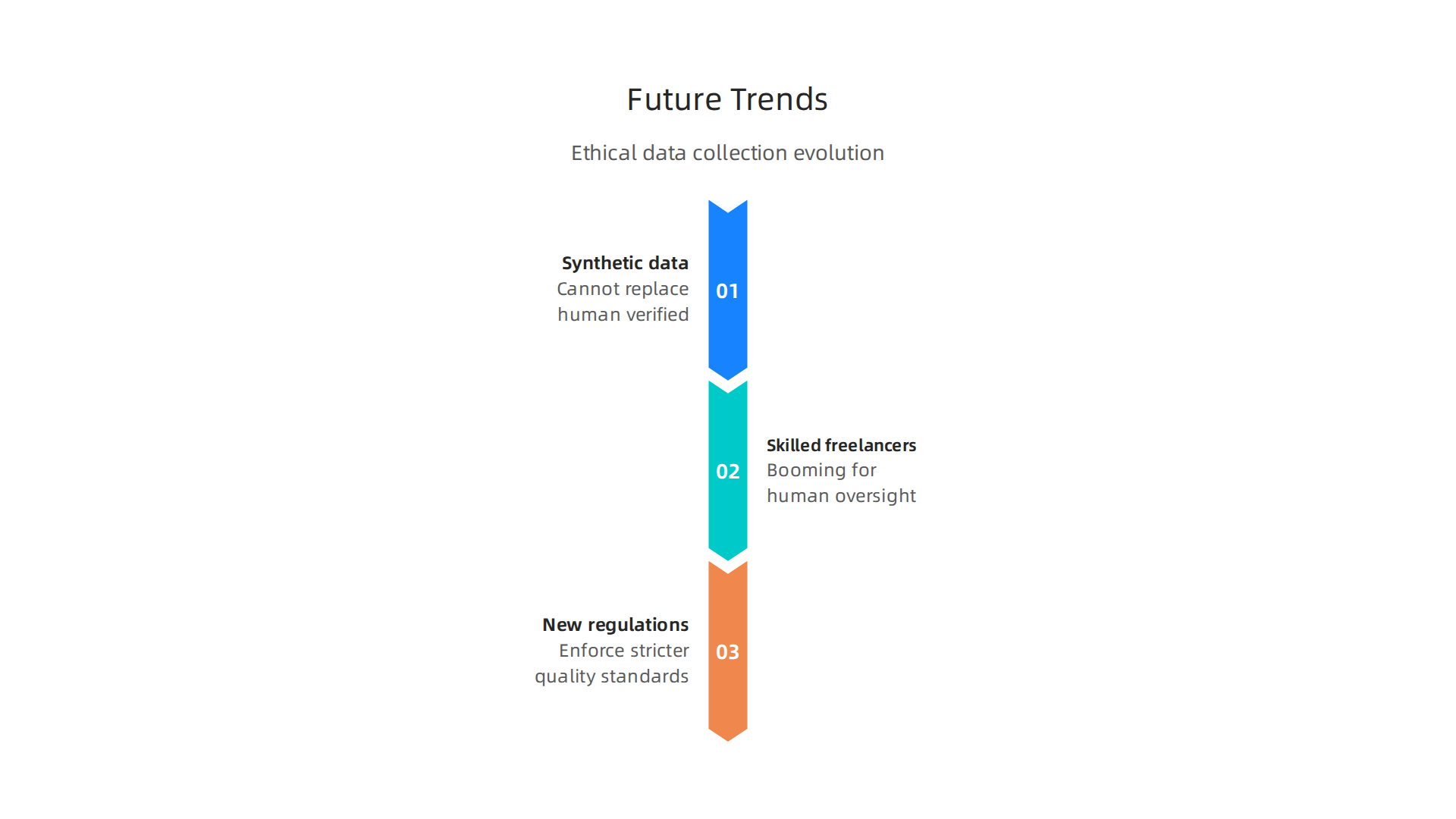
Synthetic data is on the rise, but it cannot replace human verified data.
You may have heard about synthetic data. That is AI generated data used to train other AI models. It sounds efficient. But here is the catch. Synthetic data often carries hidden biases from the original model. When you train on machine made data alone, errors can multiply. A growing body of research shows that human verified data like the kind produced through careful data annotation jobs remains essential. Real people catch edge cases and subtle mistakes that algorithms miss. The best AI systems in 2026 combine synthetic data for volume with human verified data for accuracy.
Demand for skilled freelance data entry workers is booming.
As more companies adopt AI, they need more human oversight. Every training dataset needs to be cleaned, labeled, and validated. That is why freelance data entry jobs are not going away. They are evolving. The workers who understand data quality standards and how to follow audit trails will be the most valuable. If you work through a trusted data service center, you can build a career that lasts. The skills you learn today around governance and data provenance will directly prepare you for this growing market.
New regulations enforce stricter data quality standards.
The EU AI Act is the biggest game changer. Starting in August 2026, high risk AI systems must follow strict data governance rules. According to the EU AI Act Article 10, training datasets must be relevant, representative, and properly documented. The EU AI Act Data Governance guide explains that datasets must also be sufficiently representative and free from errors. This means every piece of data needs a clear provenance trail. You need to know where it came from and how it was processed.
Compliance is not optional. Companies that ignore these rules face heavy fines. That is why the role of human data workers is more important than ever. They provide the transparency and traceability that regulations demand.
To see how these trends are already shaping user experiences, check out this field note on how everyday users are being silently shaped by invisible AI systems. It is a real world look at why ethical data collection matters right now.
The bottom line is clear: ethical data collection is not just a nice to have. It is the foundation of AI you can trust. And the people doing the data entry work are the ones building that foundation.
Summary
This article explains how poor data drives AI